
在我上学期间,为了方便学习Spark,自己在台式机和笔记本通过VMware分别搭建了一个伪分布Spark环境,从组网开始,部署操作系统、数据库、运行时环境,Spark集群 ,最后提交一个简单的wordCount到Spark集群上运行,大功告成。然而这两个Spark集群导致自己经常把大把的时间浪费在了同步数据上,最后忍无可忍,租了一个阿里云基础服务器,因为服务器已经提供了操作系统,网络等底层环境,自己仅仅部署了数据库、运行时环境、Spark集群。
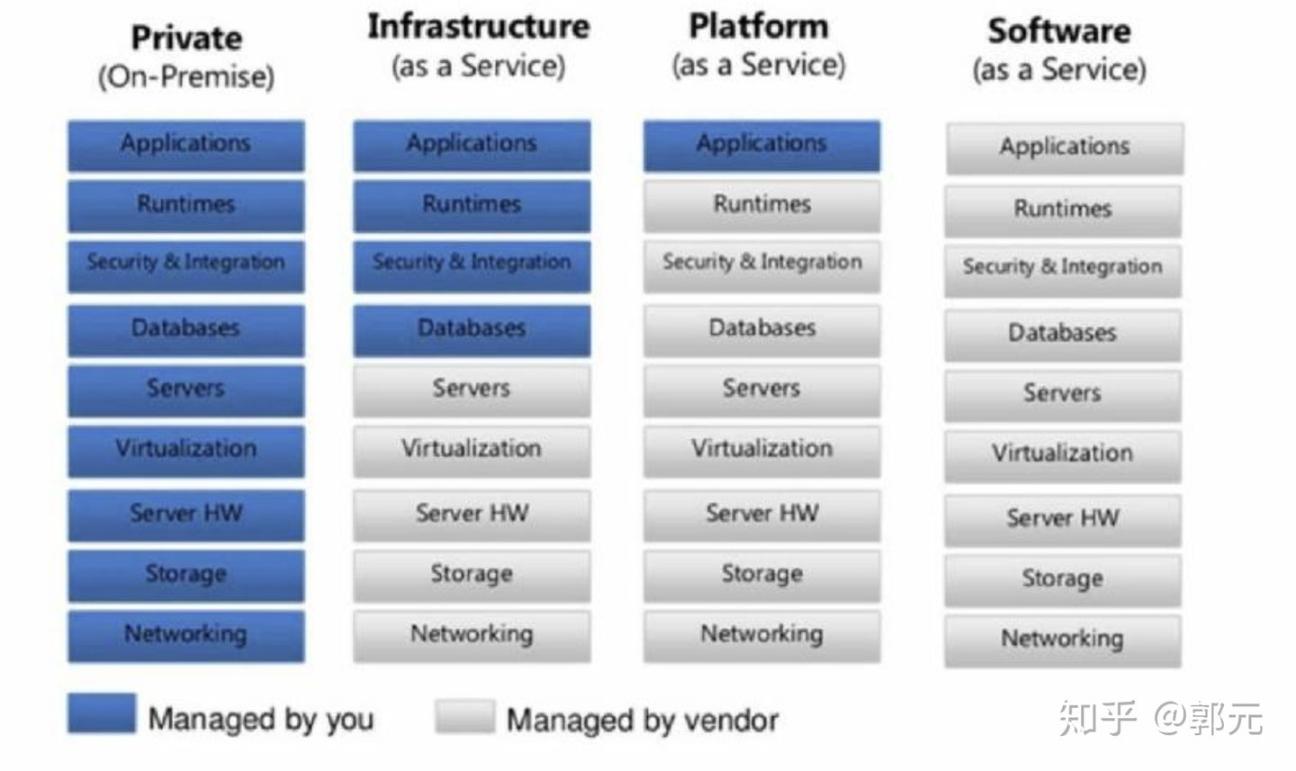
套用云计算的3种服务模式,IaaS(Infrastructure-as-a-Service)、PaaS(Platform-as-a-Service)、SaaS(Software-as-a-Service),自己从石器时代终于踏步进入了Iaas阶段。在IaaS之前,部署Applications,首先需要组网,然后部署存储、购买硬件、安装操作系统、部署数据库、安全组件、运行时环境,最后部署应用;IaaS阶段,基础服务设施即服务,只需向供应商购买相应的基础设施服务,基础设置包含了网络、虚拟化、操作系统等服务,然后在其上面部署数据库、安全组件、运行时环境、最后部署应用即可。PaaS阶段,平台即服务,平台服务包含了基本的网络、磁盘、操作系统、数据库、运行环境等,只需将应用部署到上面即可。SaaS阶段,软件设施即服务,例如Office,我们不需要经过一小时的安装,只需通过浏览器访问到其服务器端即可完成我们的需求。其发展如下图所示。
PaaS经过了好几代的更替,最开始的时候是人工的构建方式,比如我向供应商打一个电话,说”我需要一个LAMP的环境,Apache要求2.3版本,PhP要求5.3版本,MySQL需要5.5版本“,那么供应商需要人工或者通过脚本的方式去生成相应的运行平台,然后再将这个地址给我,我远程登陆即可,后来由OpenStack一直发展到以Colud Foundry为代表的开源PaaS项目,成为了当时云计算技术中的一股清流。
PaaS项目被大家接纳的一个主要原因,就是它提供了一种名叫应用托管的能力。之前用户租赁的服务器或者平台服务,用户难免会遇到云端虚拟机和本地环境不一致的问题,所以当时的云计算,比的就是谁能更好地模拟本地服务器环境,能带来更好的“上云”体验。PaaS项目是当时解决这个问题的一个最佳方案。事实上,像Cloud Foundry这样的PaaS项目,最核心的组件就是一套应用的打包和分发机制。Cloud Foundry定义了一种打包方式,将用户的可执行文件和启动脚本打进一个压缩包内,上传至云端,接着,Cloud Foundry会通过调度策略选择一个可以运行这个应用的虚拟机,然后通知这个机器将应用压缩包下载下来并启动。
这时候关键来了,由于需要在一个虚拟机上启动很多个来自不同用户的应用,Cloun Foundry会调用操作系统的Cgroups和Namespace机制为每一个应用单独创建一个称作“沙盒”的隔离环境,然后在这个“沙盒”中启动这些应用程序。这样,就实现了把多个用户的应用互不干涉地在虚拟机里批量地、自动地运行起来的目的。这正式PasS项目最核心的能力。而这些“沙盒“,就是所谓的”容器“。
在这股PaaS热潮中,当时还名叫dotCloud的Docker公司,也是其中的一份子,长期以来无人问津。眼看就要被如火如荼的PaaS风潮抛弃,dotCloud公司决定开发自己的容器项目Docker。然而,短短几个月,Docker项目就迅速崛起。Docker项目确实与Cloud Foundry的容器在大部分功能和实现原理上都是一样的,可偏偏就是这剩下的一小部分不一样的功能,成了Docker项目接下来”呼风唤雨“的不二法宝。这个功能就是Docker镜像。
Docker镜像从根本上解决了打包这个问题。所谓Docker镜像,其实就是个压缩包。但是这个压缩包里面的内容,比PaaS的应用可执行文件+启停脚本的组合就要丰富多了。实际上,大多数Docker镜像是直接由一个完整操作系统的所有文件和目录构成的,所以这个压缩包里的内容跟你本地开发和测试环境用的操作系统是完全一样的。即该镜像不论在哪儿运行,都可以得到和你本地测试时一样的环境。这正式Docker镜像的精髓。
所以,Docker项目给Paas世界带来了“降维打击”,其实是提供了一种非常便利的打包机制。这种机制直接打包了应用运行所需要的整个操作系统,从而保证了本地环境和云端环境的高度一致,避免了用户通过“试错“来匹配两种不同运行环境之间差异的痛苦过程。
解决了应用打包这个根本性的问题,同开发者与生俱来的亲密关系,再加上PaaS概念已经深入人心的完美契机,成为Docker这个技术上看似平淡无奇的项目一举走红的重要原因。
但是容器化也带了一个问题,例如我需要部署一个JavaWeb项目,用到4台物理机,A、B、C、D,A服务器部署Nginx、B、C部署Tomcat、D服务器部署MySQL服务器,他们之间的网络联通通过基本的TCP就可以访问。但是如果一旦容器化之后,例如我在A服务器上部署Docker-Nginx并将容器例如80端口映射到物理机80端口、B、C服务器上部署Docker-Tomcat并将容器例如8080端口映射到物理机8080端口、D服务器上部署MySQL服务器并将端口3306端口映射到物理机3306端口,并且我们一般容器化就是最大化利用资源,一台物理机上会部署多个Docker容器,你会发现仅端口管理就让人头大,更不用说集群的容错恢复等,那么怎么解决这个问题呢?也就是说容器的集群化有没有好的方案呢?有需求就会有产品,这个产品叫资源管理器。
Docker公司也意识到这个问题,在2014年12月的 DockerCon上发布Swarm,之后,大量围绕着Docker项目的网络、存储、监控、CI/CD,甚至UI项目纷纷出台,也涌现出了很多 Rancher、Tutum这样在开源与商业上均取得了巨大成功的创业公司。这令人兴奋的繁荣背后,却浮现出了更多的担忧。很多从业者意识到Docker项目此时已经成为Docker公司一个商业产品,而开源,只是 Docker公司吸引开发者群体的一个重要手段,更重要的是,Docker公司在Docker开源项目的发展上,始终保持着绝对的权威和发言权,并在多个场合用实际行动挑战到了其他玩家(比如,CoreOS、RedHat,甚至谷歌和微软)的切身利益。
所以这次,Google、RedHat等开源基础设施领域玩家们,共同牵头发起了一个名为CNCF(Cloud Native Computing Foundation)的基金会。这个基金会的目的其实很容易理解:它希望,以Kubernetes项目为基础,建立一个由开源基础设施领域厂商主导的、按照独立基金会方式运营的平台级社区,来对抗以Docker公司为核心的容器商业生态。
Kubernetes项目,并不是几个工程师突然“拍脑袋”想出来的东西,而是Google公司在容器化基础设施领域多年来实践经验的沉淀与升华,另一方面,kubernetes整个社区推进“民主化”架构,即:从API到容器运行时的每一层,Kubernetes项目都为开发者暴露出了可以扩展的插件机制,鼓励用户通过代码的方式介入到Kubernetes项目的每一个阶段。
Kubernetes项目的这个变革的效果立竿见影,很快在整个容器社区中催生出了大量的、基于Kubernetes API和扩展接口的二次创新工作,比如:
目前热度极高的微服务治理项目Istio;
被广泛采用的有状态应用部署框架Operator;
还有像Rook这样的开源创业项目,它通过Kubernetes的可扩展接口,把Ceph这样的重量级产品封装成了简单易用的容器存储插件。
就这样,在这种鼓励二次创新的整体氛围当中,Kubernetes社区在2016 年之后得到了空前的发展。更重要的是,不同于之前局限于“打包、发布”这样的PaaS化路线,这一次容器社区的繁荣,是一次完全以Kubernetes项目为核心的“百花争鸣”。
对于进程,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。对于 Docker等大多数Linux容器来说,Cgroups技术是用来制造约束的主要手段,而Namespace技术则是用来修改进程视图的主要方法。
首先,让我们创建一个简单的Docker容器
$ docker run --it redis /bin/sh
/ #这个命令是告诉Docker帮我们启动一个redis容器,并在容器启动之后,帮我们分配一个文本输入/输出环境。这个样子,我的电脑就变成了一个宿主机,在其上运行着一个redis容器。
然后我们在容器中执行
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
...按照常理来说,每当我们在宿主机上运行了一个/bin/sh程序,操作系统都会给它分配一个进程编号,比如PID=100,而1号进程是系统最初的进程,而现在,我们发现在容器中PID也为1,其实,Docker在内部给这个PID=100的进程施了一个“障眼法”,让他永远看不到前面其他99个进程,让它错误的以为自己就是PID=1.
这种机制,其实就是对被隔离应用的进程空间做了手脚,使得这些进只能看到重新计算过的进程编号,例如PID=1。可实际上,它们在宿主机的操作系统里,还是原来的第100号进程。这种技术,就是Linux里面的Namespace机制。Linux操作系统提供了多种Namespace,例如Mount、UTS、IPC、Network、User等,用来对各种不同的进程上下文进行“障眼法”操作。例如,Mount Namespace,用来让被隔离进程只看到当前Namespace里的挂载点信息;Network Namespace,用来让被隔离进程只能看到当前Namespace里的网络设备和配置。这就是Linxu容器最基本的实现原理了。
所以,Docker容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组Namespace参数。这样,容器就只能“看”到当前Namespace所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
所以说,容器,其实是一种特殊的进程而已,即:容器是一个“单进程”模型。这意味着,用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的Namespace参数。而Docker项目在这里扮演的角色,更多的是旁路式的辅助和管理工作。
Namesapce实现了对容器的“隔离”,我们再来谈谈容器的“限制”问题。你可以能好奇,我们不是已经通过Namespace创建了一个容器吗?为什么还要对容器进行“限制”呢?
接着上述的例子,虽然容器内的第1号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第100号进程与其他所有进程之间依然还是平等的竞争关系。这就意味着,虽然第100号进程表面上被隔离了起来,但是它所能使用到的资源(比如CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个100号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
而Linux CGroups就是Linux内核中用来为进程设置资源限制的一个重要功能。Linux CGroups的全程是Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括CPU、内存、磁盘、网络宽带等等。
我们知道Linux系统配置都是保存在文件中,所以对于Docker等Linux容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把相应的配置,例如CPU,Memory等信息填进去就可以了。
前面所说,Namespace的作用是“隔离”,它让应用进程只能看到该Namespace内的“世界”;而Cgroups的作用是“限制”,它给这个“世界”围上了一圈看不见的墙。这么一折腾,进程就真的被“装”在了一个与世隔绝的房间里,可是,这个房间四周虽然有了墙,但是如果容器进程低头一看地面,又会是怎样的一幅景象呢?即,容器里的进程看到的文件系统又是怎么样呢?
通过对Namesapce的了解,我们理所当然的想到了Mount Namesapce,Mount Nameapsce实际上修改了容器进程对文件系统的“挂载点”的认知。当然,为了能够让容器的这个根目录看起来更“真实”,我们一般会在这个容器的根目录下挂在一个完整的操作系统的文件系统,例如Ubuntu的ISO。这个样子,在容器启动之后,我们在容器里通过执行# ls /查看根目录下的内容,就是Ubuntu的所有目录和文件。而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它有一个更为专业的名字,叫做:rootfs(根文件系统)。
由于rootfs里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。这种深入到操作系统级别的运行环境一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
现在我们可以知道,对Docker项目来说,它最核心的原理实际上就是为待创建的用户进程:
1. 启用Linux Namesapce配置;
2. 设置指定的Cgroups参数。
这样一个完整的容器就诞生了。我们也可以从另外一个角度,“一分为二”的看待一个正在运行的容器:
1. 一组rootfs,这一部分我们成为“容器镜像”,是容器的静态视图;
2. 一个由Namesapce+Cgroups构成的隔离环境,这一部分我们称为”容器运行时“,是容器的动态视图。
更进一步地说,作为一名开发者,我并不关心容器运行时的差异。因为,在整个”开发-测试-发布“的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。
Kubernetes主要由Master、Node两部分组成。Master节点上运行着集群管理相关的一组进程etcd、API Server、Controller Manager、Scheduler,后三个组件构成了Kubernetes的总控中心,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且全都是自动完成。在每个Node上运行Kubelet、Proxy、Docker daemon三个组件,负责对本节点上的Pod的生命周期进行管理,以及实现服务代理的功能。

etcd:用于持久化存储集群中所有的资源对象,如Node、Service、Pod、RC、Namespace等;scheduler:集群中的调度器,负责Pod在集群节点中的调度分配。API Service:提供了资源对象的唯一操作入口,其他所有组件都必须通过它提供的API来操作资源数据,通过对相关的资源数据“全量查询”+“变化监听”,这些组件可以很“实时”地完成相关的业务功能。Contoller Manager:集群内部的管理控制中心,其主要目的是实现 Kubernetes集群的故障检测和恢复的自动化工作,比如根据Controller Manger的定义完成Pod的复制或移除,以确保Pod实例数符合Controller Manager副本的定义;根据Service与Pod的管理关系,完成服务的Endpoints对象的创建和更新;其他诸如Node的发现、管理和状态监控、死亡容器所占磁盘空间及本地缓存的镜像文件的清理等工作也是由Controller Manager完成的.kubelet:负责本Node节点上的Pod的创建、修改、监控、删除等全生命周期管理,同时Kubelet定时“上报”本Node的状态信息到API Server里。proxy:实现了Service的代理与软件模式的负载均衡器。在Docker中,我在一台服务器上创建了两个容器A、B,因为容器之间通过Namespace进行隔离,容器A、B都有自己的网络空间,Ip地址等等,假设容器A和B容器需要通过网络通讯进行交换数据,Docker允许我们将容器端口暴露给主机,通过端口映射到主机以此来达到两个容器网络通讯的目的,当然这里只介绍了一种方式,我们也可以通过共享网络栈等方式进行容器之间的通讯,我们发现这些配置比较繁琐,从另一个角度考虑,我们想有些容器就应该在一起,并且它们之间应该能够见面,也就是通过localhost的方式可以访问到,但是如果我们采用标准的容器方案的话,我们不可以这样做,除非你把两个不同的进程封装到统一个容器中,或者是容器A采用容器B的网络栈,但是这样机会存在安全方面的隐患,因此,Kubernetes给我们建立了一个新的概念,叫做Pod。
那么Pod是怎么解决上述问题的呢?如下图所示。
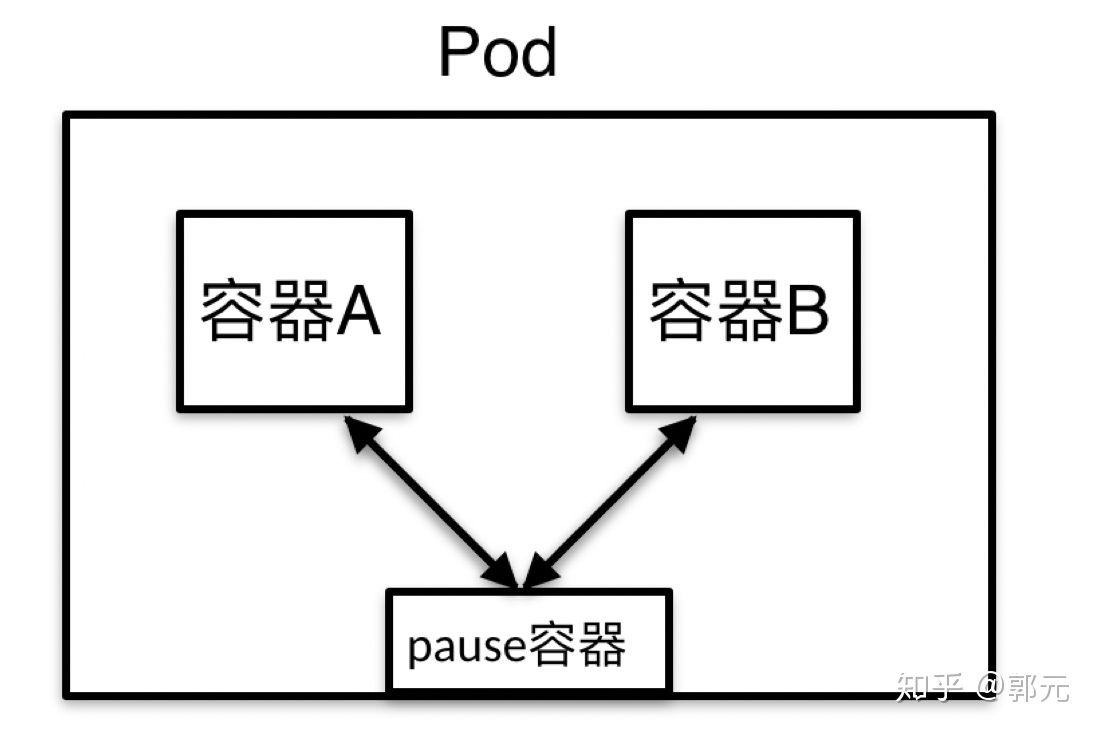
从上图可以,Pod是一组容器的集合,管理多个容器,他也是kubernetes资源管理的最小单位,例如上图的容器A、B,并且每个Pod中都存在一个特殊的容器pause,其作为Pod启动的时候启动的第一个容器,其他容器共享该容器的网络栈和Volumn挂载卷。
Pod中容器都没有自己独立的Ip地址,它们拥有的都是pause的Ip地址,即它们之间的访问就可以通过localhost的方式进行访问,也就意味着在同一个Pod中,不同容器之间的端口不能冲突。Volumn挂载卷,也就是说如果该pause挂载了一个网络存储,那么其他容器都可以访问该网络存储。该Pod中包含两个容器:Tomcat和Nginx* 编写资源清单
# vim pod.yaml
#我们使用k8s哪个版本的api
apiVersion: v1
#声明我们要创建一个Pod
kind: Pod
#设置以下Pod中包含的元数据信息
metadata:
name: myapp-pod
#设置该Pod特有的东西
spec:
#设置容器
containers:
# 该pod第一个容器的相关信息,名字叫做container1,镜像是tomcat
- name: container1
image: tomcat
imagePullPolicy: IfNotPresent
# 该pod第二个容器的相关信息,名字叫做container2,镜像是nginx
- name: container2
image: nginx
imagePullPolicy: IfNotPresent# kubectl apply -f pod.yaml
pod/myapp-pod created# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-pod 2/2 Running 0 14sPod中包含的容器# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS
94605c6c68e3 540a289bab6c "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes
52fb0c36bd76 882487b8be1d "catalina.sh run" 2 minutes ago Up 2 minutes
615e37eab4d7 k8s.gcr.io/pause:3.1 "/pause" 2 minutes ago Up 2 minutesTomcat访问8080端口 因为本地无法联通kubernetes为每个pod分配的虚拟Ip,因此进入容器本身进行测试。当然可以采用Service资源管理器进行本地访问(后面章节)。# kubectl exec myapp-pod -c container1 -it -- /bin/bash
root@myapp-pod:/usr/local/tomcat#curl localhost:8080
<!DOCTYPE html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Apache Tomcat/8.5.47</title>
......第一个Pod创建完成,如果这个时候,该Pod所在的节点宕机了,即该Pod被杀死了。
# kubectl delete pod myapp-pod
pod "myapp-pod" deleted
# kubectl get pod
No resources found.我们发现我们创建的Pod没有了,但是有时候我们的想法是这个样子的:给我部署一个Tamcat服务器,如果该Tomcat挂掉了,给我重新启动一个,这个时候怎么办呢?其实,在Kubernetes中给我们提供了多种部署Pod的方式,主要分为两种:
Pod:即在yaml中指定Kind=Pod的方式。Pod:Kubernetes内置了多种控制器管理Pod,例如Replication Controller,我们可以直接指定Kind=Replication Controller即可,我们可以设定副本数=1,那么Kubernets会自动创建/删除Pod维持我们的期望Pod数目。下图所示了Kubernetes常用的控制器。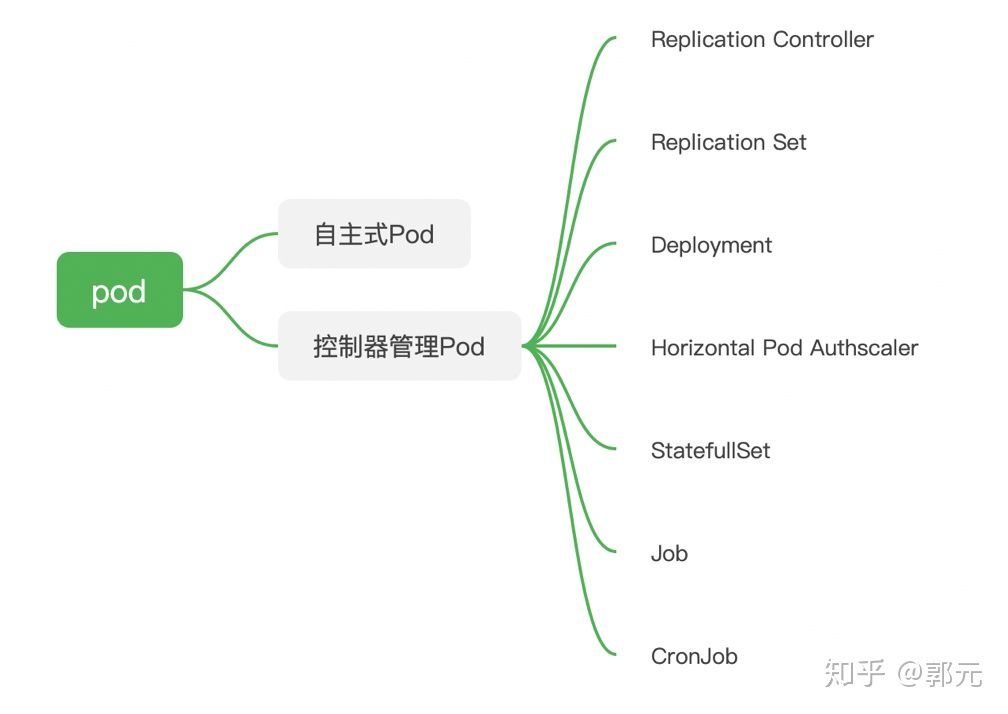
Replication Controller(RC)用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来代替;而异常多出来的容器也会自动回收。所以RC的定义包含以下几个部分:
Pod期待的数目(replicas)。Pod的Label Selector。Label即标签的意思,可以附加到各种资源上,例如Node、Pod、Rc、Serice等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源上去。随后可以通过Label Selector(标签选择器)查询和筛选有某些Label的资源对象。 不同控制器内部就是通过Label Selector来筛选要监控的Pod,例如RC通过Label Selector来选择要监控Pod的副本数。所以我们在编写不同的控制器的时候一般都需要配置Label Selector。 * 当Pod的副本数小于预期数目的时候,用户创建新的Pod的模板(template)
Pod包含一个容器Tomcat,Pod通过RC控制器管理,维持副本数为3 * 编写资源清单
# vim rc.yaml
#我们使用k8s哪个版本的api
apiVersion: v1
#声明我们要创建一个RC
kind: ReplicationController
#设置以下RC中包含的元数据信息
metadata:
name: myapp-rc
#设置该RC特有的东西
spec:
#副本数为3
replicas: 3
#选择器,该RC只管理label_1_key=label_1_value的Pod,如果不存在通过template创建
selector:
label_1_key: label_1_value
template:
metadata:
labels:
#该Pod上添加 label_1_key=label_1_value
label_1_key: label_1_value
spec:
#设置容器
containers:
# 该pod第一个容器的相关信息,名字叫做container1,镜像是tomcat
- name: container1
image: tomcat需要注意的是spec.template.metadata.labels指定了该Pod的标签,这里的标签需要和spec.selector相匹配,否则此RC每次创建一个无法匹配的Label的Pod,就会不断地尝试创建新的Pod,最终陷入“只为他人做嫁衣“的悲惨世界中,永无翻身之时。
# kubectl apply -f rc.yaml
replicationcontroller/myapp-rc created# kubectl get rc
NAME DESIRED CURRENT READY AGE
myapp-rc 3 3 3 4s
# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-rc-9ddjv 1/1 Running 0 13s
myapp-rc-j6w6m 1/1 Running 0 13s
myapp-rc-qv9tx 1/1 Running 0 13smyapp-rc-9ddjv的Pod,验证RC时候是否会自动创建新的Pod。# kubectl delete pod myapp-rc-9ddjv
pod "myapp-rc-9ddjv" deleted# kubectl get rc
NAME DESIRED CURRENT READY AGE
myapp-rc 3 3 3 15m
# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-rc-j6w6m 1/1 Running 0 15m
myapp-rc-p5rbv 1/1 Running 0 61s
myapp-rc-qv9tx 1/1 Running 0 15m我们发现RC帮我们创建了一个新的Pod:myapp-rc-p5rbv
# kubectl edit pod myapp-rc-j6w6m
labels:
10 label_2_key: label_2_value
pod/myapp-rc-j6w6m edited# kubectl get rc
NAME DESIRED CURRENT READY AGE
myapp-rc 3 3 3 36m
# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
myapp-rc-j6w6m 1/1 Running 0 40m label_2_key=label_2_value
myapp-rc-lkt4p 1/1 Running 0 85s label_1_key=label_1_value
myapp-rc-p5rbv 1/1 Running 0 26m label_1_key=label_1_value
myapp-rc-qv9tx 1/1 Running 0 40m label_1_key=label_1_value由于myapp-rc-j6w6m标签修改,导致该Pod不受RC管理,所以RC为了维持副本数为3,为我们重新创建了一个新的Pod。
Replication Set(RS)跟Replication Controller没有本质的不同,只是名字不一样,并且Replication Set支持集合式的selector。
RS的定义与RC的定义很类似,除了API和Kind类型有所区别:
apiVersion: extensions/v1beat1
kind: ReplicaSetDeployment为Pod和RS提供了一个声明时定义方法,用来替代以前RC来方便的管理应用,其提供了Pod的滚动升级和回滚特性,主要应用场景包括。
Deployment来创建Pod和RS。Deployment。Deployment的定义与RS的定义很类似,除了API和Kind类型有所区别:
apiVersion: extensions/v1beta1
kind: Deployment# vim deployment.yaml
#我们使用k8s哪个版本的api
apiVersion: extensions/v1beta1
#声明我们要创建一个Deployment
kind: Deployment
#设置以下Deployment中包含的元数据信息
metadata:
name: myapp-deployment
#设置该RC特有的东西
spec:
#副本数为3
replicas: 3
#选择器,该Deployment只管理label_1_key=label_1_value的Pod,如果不存在通过template创建
selector:
matchLabels:
label_1_key: label_1_value
template:
metadata:
labels:
#该Pod上添加 label_1_key=label_1_value
label_1_key: label_1_value
spec:
#设置容器
containers:
# 该pod第一个容器的相关信息,名字叫做container1,镜像是tomcat
- name: container1
image: tomcat
imagePullPolicy: IfNotPresent# kubectl apply -f deployment.yaml
deployment.extensions/myapp-deployment created
# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
myapp-deployment 3/3 3 3 6sHorizontal Pod Authscaler简成HPA,意思是Pod自动横向扩容,它也是一种资源对象。通过追踪分析所有控制Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理。当前,HPA可以有以下另种方式作为Pod负载的度量指标。
CPUUtilizationPrecentage。TPS或者QPS)。HPAvim hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
kind: Deployment
name: myapp-deployment
targetCPUUtilizationPercentage: 90# kubectl apply -f hpa.yaml
horizontalpodautoscaler.autoscaling/myapp-hpa created
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-hpa Deployment/myapp-deployment <unknown>/90% 1 10 0 7sStatefullSet是为了解决有状态服务的问题(对应Deployment和RS是为无状态服务而设计),其应用场景包括:
Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现。Pod重新调度后其PodName和hostName不变,基于Headless Service(即没有Cluster IP的Service)来实现。Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行,基于init containers来实现。DaemonSet确保全部(或者一些)Node上运行一个Pod副本。当有Node加入集群时,也会为它们创建一个新的Pod。当有Node从集群中移除的时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。 使用DemonSet的一些典型用法:
Daemon,例如在每个Node上运行gluster、ceph。Node上运行日志收集daemon,例如fluentd、logstash。Node上运行监控daemon,例如Prometheus Node Exporter。Job负责批处理任务,即仅执行一次的任务,它确保批处理任务的一个或者多个Pod成功运行。
Cron Job管理基于时间的Job。即
假设kubernetes集群中运行了好多pod,kubernetes在创建每个Pod的时候会为每个Pod分配了一个虚拟的Pod Ip地址,Pod Ip是一个虚拟的二层网络,集群之间不同机器之间Pod的通讯,其真实的TCP/IP流量是通过Node节点所在的物理网卡流出的(Node IP)。由于Pod Ip是kubernetes集群内部的一些私有Ip地址,因此kubernetes集群内部的程序才可以访问Pod,kubernetes集群之外的程序没有办法访问。
然而我们部署的许多应用都需要提供给外部客户端访问,因此,我们可以可以通过kubernetes的服务发现(Service),将这些服务暴露给我们的客户端,那么客户端就可以通过Ip+Port的方式访问至我们的多个Pod。为什么说是多个Pod呢?因为Service为我们提供了复杂均衡机制。例如我们通过Deployment部署了一个Tomcat,replicas设置为3,Service提供了多种负载均衡策略,针对不同的请求路由到不同的Pod上。如下图所示。
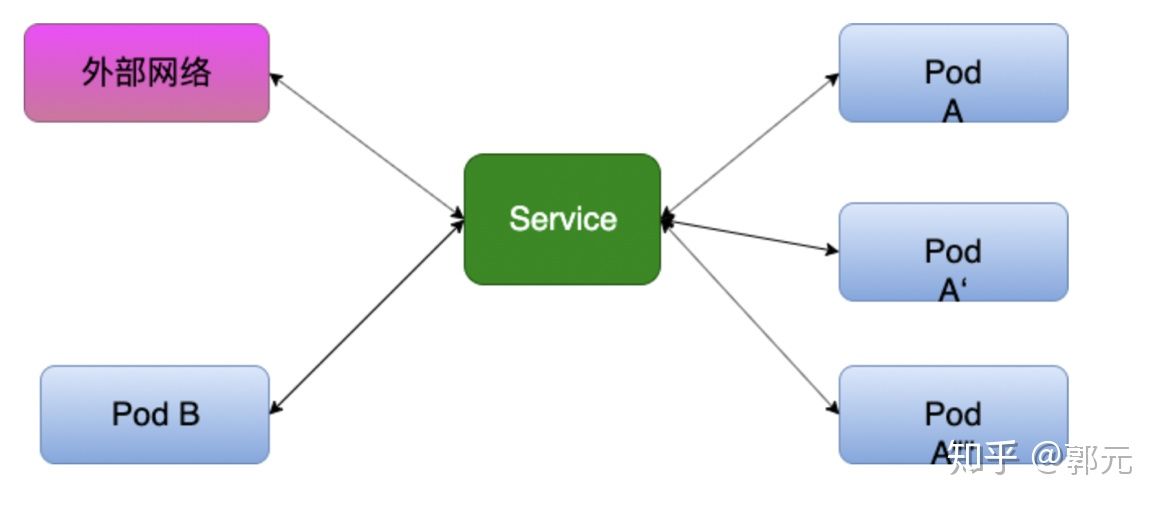
采用微服务架构时,作为服务所有者,除了实现业务逻辑外,我们也需要考虑应该怎样发布我们的服务,例如发布的服务中哪些服务不需要暴露给客户端,仅仅在服务内部之间使用,哪些服务我们又需要暴露出去,因此,kubernetes给我们提供了多种灵活的服务发布方式,主要包括:ClusterIp、NodePort、LoadBalancer等,其关系如下图所示。
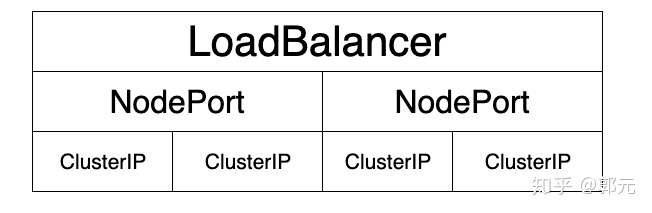
当我们发布服务的时候,Kubernetes会为我们的服务默认分配一个虚拟的IP,即ClusterIp,这也是Service默认的类型。ClusterIp更像是一个“伪造”的IP网络,原因有以下几点:
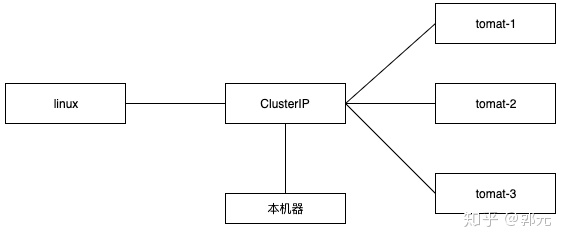
Cluster IP仅仅作用于Kubernetes Service这个对象,并有Kubernetes管理和分配IP地址(来源于ClusterIP地址池)。Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。Cluster IP只能结合Service Port组成一个具体的通讯端口,单独的Cluster IP不具备TCP/IP通讯的基础,并且它们属于Kubernetes集群这个一个封闭的空间,集群之外的节点如果要访问这个通讯端口,则需要做一些额外的工作。Kubernetes集群之外,Node Ip网、Pod IP网于Cluster IP网之间的通讯,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP路由有很大的不同。通过Deployment部署一个Tomcat,replcas设置为3,并通过ClusterIP的方式注册tomcat为Service,另外我们创建一个Nginx Pod,通过Nginx Pod测试是否能访问该服务,另外我们通过本机是否能Ping通该服务。其结构如下。
TomcatService# vim myapp-deploy-tomcat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-tomcat
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp-tomcat
template:
metadata:
labels:
app: myapp-tomcat
spec:
containers:
- name: myapp-tomcat
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: myapp-service-tomcat
namespace: default
spec:
type: ClusterIP
selector:
app: myapp-tomcat
ports:
- name: http
port: 8080
targetPort: 8080LinuxPodvim myapp-pod-tomca.yaml
#我们使用k8s哪个版本的api
apiVersion: v1
#声明我们要创建一个Pod
kind: Pod
#设置以下Pod中包含的元数据信息
metadata:
name: myapp-pod-tomcat
#设置该Pod特有的东西
spec:
#设置容器
containers:
- name: myapp-pop-tomcat
image: tomcat
imagePullPolicy: IfNotPresentLinuxPod中访问Service# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-deploy-tomcat-bdc87ddf7-69nsg 1/1 Running 0 31m
myapp-deploy-tomcat-bdc87ddf7-8xz6f 1/1 Running 0 31m
myapp-deploy-tomcat-bdc87ddf7-wpt7s 1/1 Running 0 31m
myapp-pod-tomcat 1/1 Running 0 2m9s
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 35m
myapp-service-tomcat ClusterIP 10.103.250.70 <none> 8080/TCP 32m
#kubectl exec myapp-pod-tomcat -it -- /bin/bash
root@myapp-pod-tomcat:/usr/local/tomcat# curl 10.103.250.70:8080
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>......TomcatService# curl localhost:8080
curl: (7) Failed to connect to localhost port 8080根据上述的分析和总结,我们基本明白了:Service的Cluster IP属于Kubernetes集群内部的地址,无法在集群外部直接使用这个地址。那么矛盾来了,实际上我们开发的许多业务中肯定有一部分服务是要提供给Kubernetes集群外部的应用或者用户来访问的,典型的就是Web端的服务模块,比如上面的tomcat-server,因此我们在发布Service的时候,可以采用NodePort的方式。
NodePort的实现方式是在Kubernetes集群中的每个Node上为需要外部访问的Service开启一个对应的TCP监听端口,外部系统只要使用任意一个Node的Ip+具体的NodePort端口号即可访问此服务。
TomcatService# vim myapp-node-port-tomcat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-tomcat
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp-tomcat
template:
metadata:
labels:
app: myapp-tomcat
spec:
containers:
- name: myapp-tomcat
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: myapp-service-tomcat
namespace: default
spec:
type: NodePort
selector:
app: myapp-tomcat
ports:
- name: http
port: 8080
targetPort: 8080# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 47m
myapp-service-tomcat NodePort 10.96.174.55 <none> 8080:30038/TCP 5m45s
# curl localhost:30038
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Apache Tomcat/8.5.47</title>
<link href="f......但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的额集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需访问此负载均衡器的IP地址,又负载均衡器负责转发流量到后面某个Node的NodePort上,如下图所示。
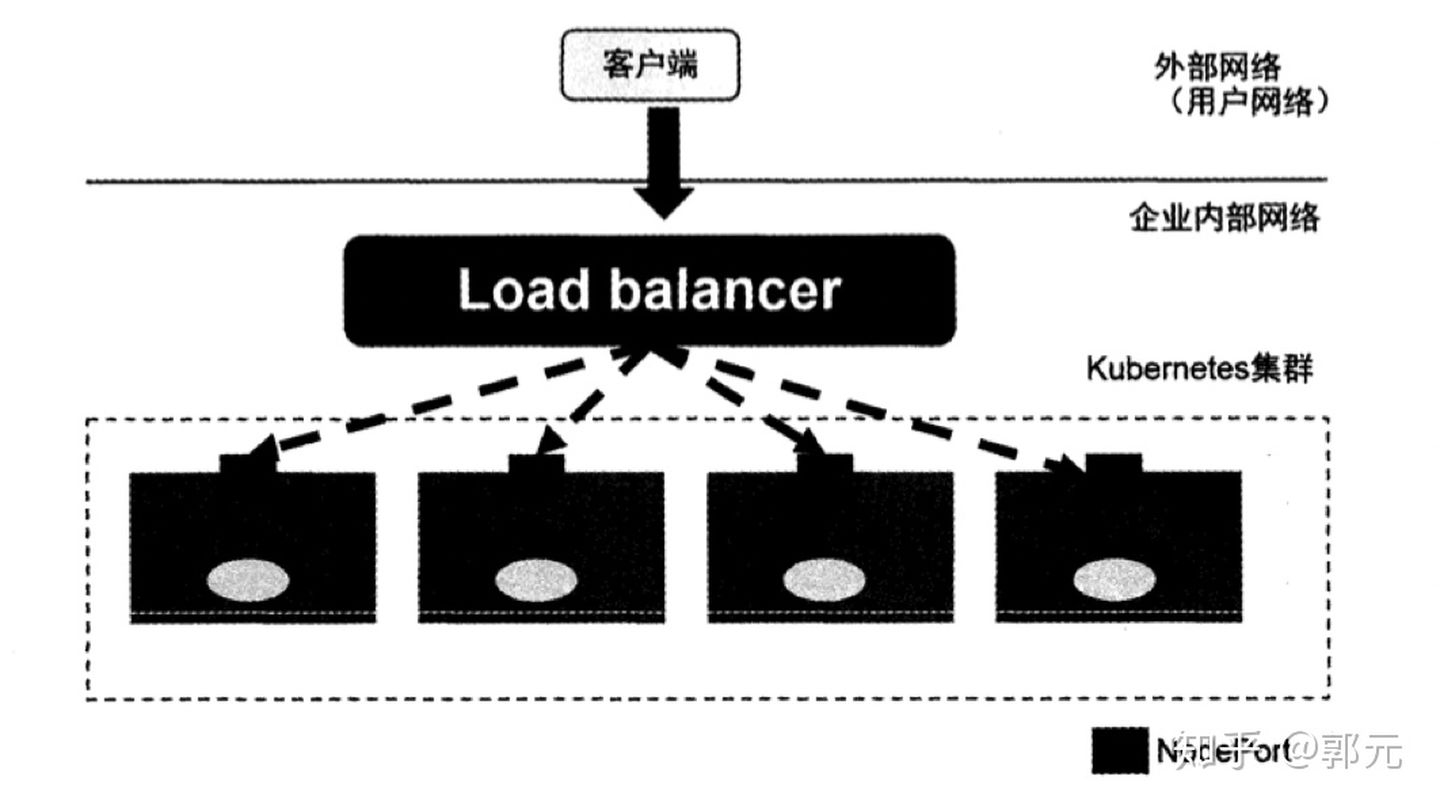
上图中的Load Balancer组件独立于Kubernetes集群之外,通常是一个硬件的负载均衡器,或者是以软件方式实现的,例如HAProxy或者Nginx。对于每个Service,我们通常需要一个对应的Load Balancer实例来转发流量到后端的Node上,这的确增加了工作量和出错的概率。于是Kubernetes提出了自动化的方案,如果我们的集群运行在谷歌的GCE公有云上,那么我们只要把Service的type=NodePort改成Node=LoadBalancer,此时Kubernetes会自动创建一个对应的Load Balancer实例并返回它的IP地址供外部客户端使用。其他公有云提供商只要实现了支持此特性的驱动,则也可以达到上述目的。此外,裸机上的类似机制(Bare Meta Service Load Balancers)也正在被开发中。
对于服务,我们经常将其分为两大类:有状态服务、无状态服务。有状态服务常见的例如DBMS等,有状态服务常见的例如调度器,Apache等。对于Docker来说,其更适应于无状态服务,但是Kubernetes的目标是作为未来基础设施的平台,其必须要攻克有状态服务,那有状态服务有些数据需要持久化,需要保存起来,因此,kubernetes引入了多种存储,例如ConfigMap(专门用来存储配置文件,就像配置文件中心)、Secret(存储一些需要加密的数据)、Volumn(用来存储一些数据)、PV(Persistent Volumn,一个动态的存储)。
ConfigMap功能在Kubernetes1.2版本中引入,许多应用程序会从配置文件、命令行参数或者环境变量中读取配置信息。ConfigMap API给我们提供了想容器中注入配置信息的机制,ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制大对象。
ConfigMap可以使用目录创建、使用文件创建、使用字面值创建。
# ls ./configmap
a.properties
b.properties
# cat a.properties
a1=a1
a2=a2
# cat b.properties
b1=b1
b2=b2
# kubectl creatte configmap my-config --from-file=./configmap-from-file指定在目录下的所有文件都会在ConfigMap里面创建一个键值对,键的名字就是文件名,值就是文件的内容 *
只要指定一个文件就可以从单个文件中创建ConfigMap
# kubectl create configmap my-config --from-file=./configmap/a.properties-from-file这个参数可以使用多次,你可以使用两次分别制定上个例子中的那两个配置文件,效果就跟指定整个目录是一样的。
使用字面值创建,利用-from-litteral参数传递配置信息,该参数可以使用多次,格式如下
# kubectl create configmap my-config --from-literal=log.level=warnConfigMap来代替环境变量# vim configmap-env.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm
---
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO
---
apiVersion: v1
kind: Pod
metadata:
name: configmap-test
spec:
containers:
- name: configmap-test
image: tomcat
command: ["/bin/sh","-c","env"]
env:
- name: SPECIAL_LEVLE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.type
envFrom:
- configMapRef:
name: env-config
restartPolicy: Never
# kubectl get cm
NAME DATA AGE
env-config 1 3m24s
special-config 2 3m24s
# kubectl get pod
NAME READY STATUS RESTARTS AGE
configmap-test 0/1 Completed 0 3m27s
# kubectl log configmap-test
log_level=INFO
SPECIAL_TYPE_KEY=charm
SPECIAL_LEVLE_KEY=veryConfigMap# vim configmap-volumn.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm
---
apiVersion: v1
kind: Pod
metadata:
name: configmap-volumn
spec:
containers:
- name: configmap-volumn-test
image: tomcat
command: ["/bin/sh","-c","sleep 6000s"]
volumeMounts:
- name: config-volumn
mountPath: /etc/config
volumes:
- name: config-volumn
configMap:
name: special-config
restartPolicy: Never
# kubectl exec configmap-volumn -it -- /bin/bash
root@configmap-volumn:/etc/config# ls /etc/config
special.how special.type
root@configmap-volumn:/etc/config# cat /etc/config/special.how
verySecret解决了密码、token、密钥等敏感数据的配置,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。
Secret可以以Volumn或者环境变量的方式使用
Secret有三种类型:
ServiceAccount:用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录中;Opaque:base64编码格式的Secret,用来存储密码、密钥等;kubernetes.io/dockerconfigjson:用来存储私有docker registry的认证信息。Opque类型的数据是一个map类型,要求value是base64编码格式:
# echo -n "admin"|base64
YWRtaW4=
# echo -n "guoyuan_password"|base64
Z3VveXVhbl9wYXNzd29yZA==
# vim secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: Z3VveXVhbl9wYXNzd29yZA==
---
apiVersion: v1
kind: Pod
metadata:
name: secret-test
spec:
volumes:
- name: secrets
secret:
secretName: mysecret
containers:
- image: tomcat
name: db
volumeMounts:
- name: secrets
mountPath: "/etc/secrets"
readOnly: true
#kubectl exec secret-test -it -- /bin/bash
root@secret-test:/usr/local/tomcat# cat /etc/secrets/username
admin
root@secret-test:/usr/local/tomcat# cat /etc/secrets/password
guoyuan_password容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,Kubelet会重启它,但是容器中的文件将丢失--容器以干净的状态(镜像最初的状态)重新启动。其次,在Pod中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes中的Volumn抽象就很好的解决了这些问题。目前,Kubernetes支持多种类型的Volumn,例如GlusterFs、Ceph等先进的分布式文件系统。
Volumn的使用也比较简单,在大多数情况下,我们现在Pod上声明一个Volumn,然后在容器里引用该Volumn并Mount到容器里的某个目录上。举例来说,我们要给之前Tomcat Pod增加一个名字为dataVol的Volumn,并且Mount到容器的/my>Pod的定义文件做如下修改即可
spec:
volumns:
- name: datavol
emptyDir: {}
containers:
- name: tomcat
iamge: tomcat
volumeMounts:
- mountPath: /mydata-data
name: datavol上面例子中emptyDir是Volumn的一种类型,Kubernets提供了丰富的Volumn类型。
一个emptyDir Volumn是在Pod分配到Node时创建的,从它的名字可以看出,他的初始化内容为空,并且无需指定宿主机上对应的目录文件,因为这是Kubernetes自动分配的一个目录,当Pod从Node上移除时,emptyDir中的数据也会被永久删除。
hostPath为在Pod上挂载宿主机上的文件或目录。在下面的例子中使用宿主机的/data定义了一个hostPath类型的Volumn:
volumes:
- name: "persistent-storage"
hostPath:
path: "/data"之前我们提到的Volumn是定义在Pod上的,属于“计算资源”的一部分,而实际上,“网络存储”是相对独立于“计算资源”而存在的一种实体资源。比如在使用虚拟机的情况下,我们通常会先定义一个网络存储,然后从中划出一个“网盘”并挂在到虚拟机上。Persistent Volumn(简称PV)和与之关联的Persistent Volumn Clain(简称PVC)也起到了类似的作用。
PV可以理解成Kubernetes集群中的某个网络存储中对应的一块存储,它与Volumn很类似,但有以下区别。
PV只能是网络存储,不属于任何Node,但可以在每个Node上访问。PV并不是定义在Pod上的,而是独立于Pod之外定义。PV目前只有一种类型:GCE Persistent Disks、NFS、RBD、iSCSCI、AWS ElasticBlockStore、CluserFS等。下面给出了NFS类型PV的一个yaml定义声明,声明了需要5Gi的存储空间:
apiVersion: v1
kind: PersistentVolumn
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /somepath
server: 172.17.0.2如果某个Pod想申请某种条件的PV,则首先需要定义一个PersistentVolumnClaim(PVC)对象:
kind: PersistentVolumnClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi然后在Pod的Volumn定义中引用上述PVC即可:
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板