
本文将向您介绍有关 GPT-4 Vision 的所有信息,从访问它到动手进入现实世界的示例,以及它的局限性。

GPT-4V 于 2022 年接受训练,具有独特的理解图像的能力,而不仅仅是识别物体。它查看来自互联网和其他来源的大量图像,类似于在阅读标题时翻阅巨大的相册。它理解上下文、细微差别和微妙之处,使其能够像我们一样看待世界,但具有机器的计算能力。
GPT-4V 利用先进的机器学习技术来解释和分析视觉和文本信息。它的实力在于它对庞大数据集的训练,其中不仅包括文本,还包括来自互联网各个角落的各种视觉元素。
训练过程结合了强化学习,增强了 GPT-4 作为多模态模型的能力。
但更有趣的是两阶段的训练方法。最初,该模型已准备好掌握视觉语言知识,确保它理解文本和视觉之间的复杂关系。
在此之后,先进的人工智能系统对更小、更高质量的数据集进行微调。这一步对于提高其生成的可靠性和可用性至关重要,确保用户获得最准确和最相关的信息。
GPT-4 Vision 目前(截至 2023 年 10 月)仅适用于 ChatGPT Plus 和企业用户。ChatGPT Plus 每月收费 20 美元,可以从您的常规免费 ChatGPT 帐户升级到。
访问 GPT-4 Vision 的方法:


GPT-4 Vision 将高级语言建模与视觉功能相结合,为学术领域开辟了新的可能性,尤其是在破译历史手稿方面。传统上,这项任务是由熟练的古文字学家和历史学家进行的细致而耗时的工作。
我们首先给出一张图片,它似乎是一篇旧报纸文章的一部分:
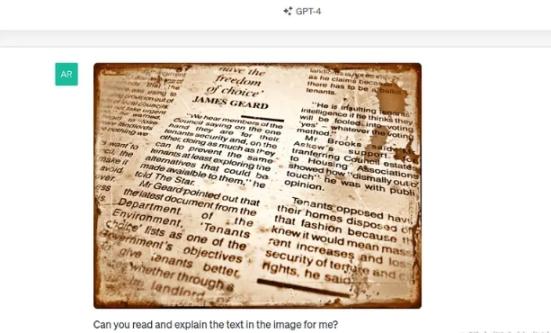
该模型能够读取、破译内容并提供分析,同时提供现实的答案,即图像的某些部分被截断和遮挡。
GPT-4 愿景可以在提供所需设计的视觉图像时为网站编写代码。它从视觉设计到网站的源代码。该模型的这种单一功能可以大大减少构建网站所需的时间。
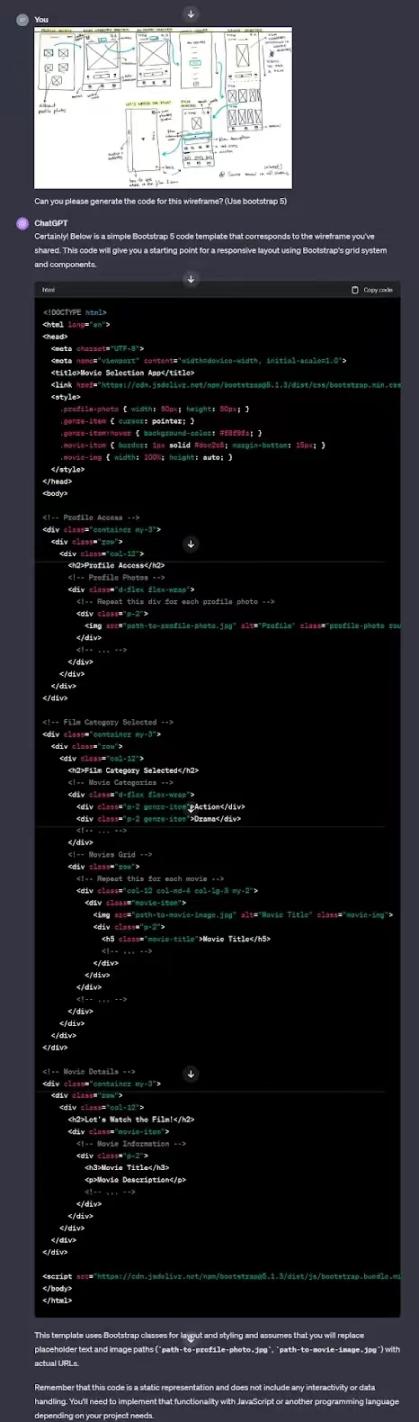
让我们用手绘的简单设计来提示 GPT-4 Vision,用于博客网站。
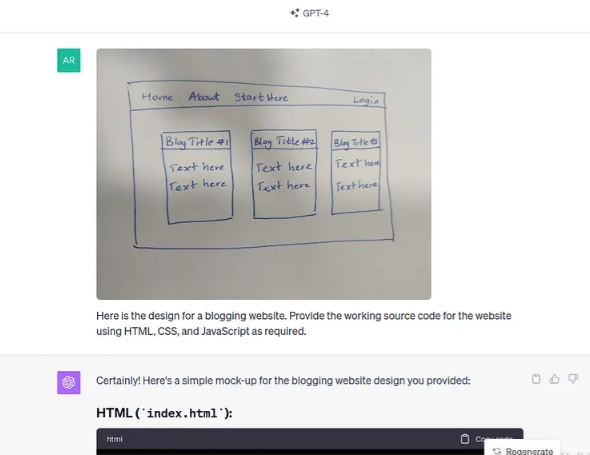
一旦它提供了源代码,我们只需按照说明复制粘贴并创建 HTML 和 CSS 文件。以下是该网站的外观:
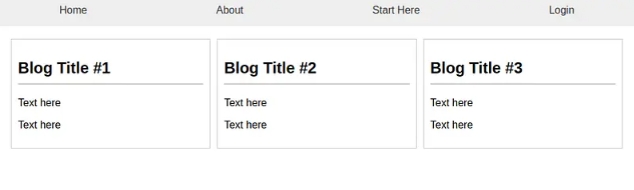
它看起来不是惊人的相似吗?当然,我们举了一个简单的例子,但你可以从这里开始,在很短的时间内开发一个更复杂和量身定制的网站,这要归功于新引入的 GPT-4 Vision 模型。
该模型能够分析数据可视化,以解释基础数据,并基于可视化提供关键见解。为了测试这个功能,我们可以简单地给出一个图并征求见解。

虽然它在理解绘图的整体上下文和线性趋势方面做得很好,但它将起始年份提到为 1950 年会出错,尽管数据点仅从 1960 年开始。该模型还推导出人口增长和经济发展等因素——虽然它们可能是正确的,但这些见解不能仅从这张特定的图表中得出。
人们可以提出多个后续问题来完善 GPT-4 Vision 模型的初始输出。根据我们的测试,仍然需要人工参与来审查见解,并且该模型可以提高数据解释用例的生产力。
随着 ChatGPT 的出现,社交媒体上充斥着各种提示工程技术,许多人发现了令人惊讶的创造性方法来利用生成技术来发挥自己的优势。
在本教程中,我们将使用 DALL-E-3(在 ChatGPT Plus 中也可用)和 GPT-4 Vision,创造性地创建社交媒体帖子。
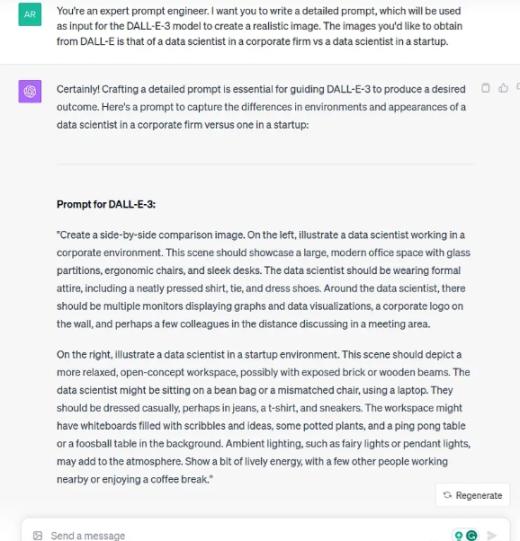
第 2 步:使用提示符并从 DALL-E 生成图像。您可以调整和完善提示,直到您对输出感到满意为止。

第 3 步:使用图像并要求 GPT-4 Vision 创建一个与图像并排的帖子。
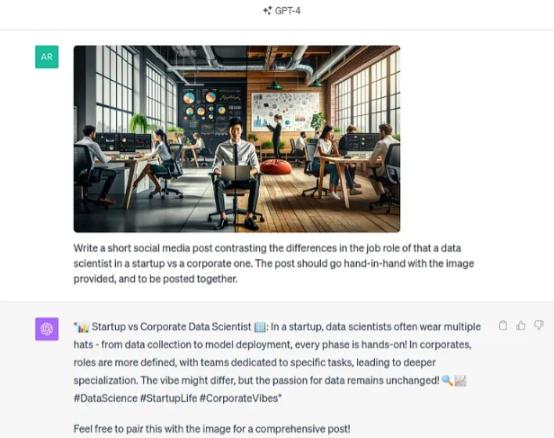
通过调整和提供更详细的提示,可以获得更好的输出,并可以进一步探索创意内容的生成。值得注意的是,不建议在互联网或社交媒体上发送带有 AI 生成内容的垃圾邮件,因为这些内容有其自身的局限性。相反,用你自己的经验进行事实核查和完善。
当然,这并不是一个可能的用例的详尽列表——GPT-4 Vision 具有更多功能。相反,将其视为通过将技术应用于您选择的领域来探索您的好奇心的灵感和起点。
因为自 2023 年 3 月推出 GPT-4 以来,OpenAI 自己又花了几个月的时间,通过内部和外部的“红队”练习对其进行测试,以确定这种生成技术的缺点,他们在系统卡中概述了这些缺点。
虽然 GPT-4 模型代表了可靠性和准确性的重大进步,但情况并非总是如此。根据 OpenAI 的说法,根据内部测试,GPT-4 Vision 有时仍然可能不可靠和不准确。该团队甚至提到“ChatGPT 可能会犯错误。
根据 OpenAI 的说法,与其前辈类似,GPT-4 Vision 继续强化社会偏见和世界观,包括对某些边缘化群体的有害刻板印象和贬低性联想。因此,重要的是要了解这一限制并采取其他必要步骤来处理用例本身的偏差,而不是依赖模型来解决它。
除了偏见问题外,与 ChatGPT 共享的数据还可用于训练模型,除非选择退出;因此,请务必注意不要与模型共享任何敏感或私人信息。用户还可以通过进入“设置和测试版”部分下的“数据控件”来选择不共享数据以改进模型。
GPT-4 Vision 无法回答要求识别图像中特定个体的问题。这是设计上预期的“拒绝”行为。此外,OpenAI 建议不要在高风险任务上使用 GPT-4 Vision,其中包括:
因此,作为用户,我们需要在负责任地使用 GPT-4 Vision 时保持警惕,尤其是在上述高风险任务和敏感环境中。
import os
import requests
import base64
# Configuration
GPT4V_KEY = "YOUR_API_KEY"
encoded_image = base64.b64encode(open(IMAGE_PATH, 'rb').read()).decode('ascii')
headers = {
"Content-Type": "application/json",
"api-key": GPT4V_KEY,
}
# Payload for the request
payload = {
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant that helps people find information."
}
]
}
],
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 800
}
GPT4-V_ENDPOINT = "https://xx.openai.azure.com/openai/deployments/gpt-4-vision-preview/chat/completions?api-version=2023-07-01-preview"
# Send request
try:
response = requests.post(GPT4-V_ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.RequestException as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
# Handle the response as needed (e.g., print or process)
print(response.json()) Ai助手
Ai助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板