导语:3月17日百度发布文心一言,网友们疯狂发散想象力,令人捧腹的图片接连被生成。关于文心一言文字生成图片的讨论热情空前高涨。
2023年的AI绘画领域是由两家公司的动态引爆的。
3月17日百度发布文心一言,网友们疯狂发散想象力,令人捧腹的图片接连被生成。关于文心一言文字生成图片的讨论热情空前高涨。
紧接着,3月18日,美国Midjourney公司宣布第五版AI图像生成服务,即MidjourneyV5。本来就处在行业领先水平的Midjourney,这一次版本更新真正让AI绘画圈沸腾了。因为MidjourneyV5生成的图片堪称惊艳。
两个系统几乎同时发布,免不了被对比。深燃体验后发现,文心一言的图片生成功能,能够识别简单元素、文本没有歧义的人或事物,但涉及到成语、专有名词,以及字面意思和实际意义不同的表述,它就会跑偏。Midjourney在这方面几乎没什么问题。另外,Midjourney接收到的提示词(prompt)越详细精准,生成的图片越符合要求,但文心一言需求越多,系统越容易出错。
调侃背后,AI生成图片其实不是一件简单的事情,需要在数据、算法、算力等方面综合发力,既对技术和硬件有高要求,还对数据采集和标注等苦活累活高度依赖。文心一言的AI绘图功能与Midjourney在以上三方面都有不小的差距。
百度方面公开表示,“大家也会从接下来文生图能力的快速调优迭代,看到百度的自研实力。文心一言正在大家的使用过程中不断学习和成长,请大家给自研技术和产品一点信心和时间。”从业者预估,文心一言全力追赶,用一年左右的时间有希望达到国外80%以上的水平。
AI绘图这个战场,枪声已经打响,追逐赛、排位赛都将一轮轮上演。

搞不定成语和专有名词,
文心一言最近接受的最大考验,莫过于画一幅中餐菜名图。在网友们的热情创作下,驴肉火烧、红烧狮子头等菜品出来的画做一个比一个离谱,车水马龙的街道、虎头虎脑的大胖小子,同样惊掉了大家的下巴。
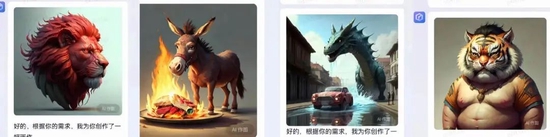
网友体验文心一言时截图,目前已更新
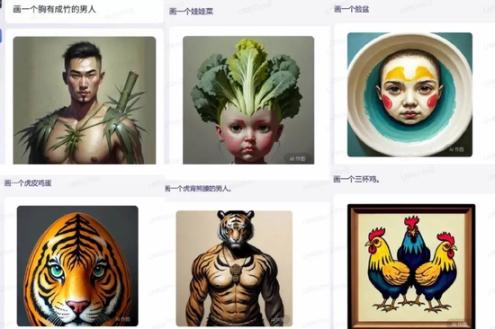
网民热心找bug,百度程序员应该也在背后发力,深燃测试发现,以上内容均已更新为可以正确显示对应图片。不过,像娃娃菜、脸盆、虎皮鸡蛋、三杯鸡,还有胸有成竹的男人、虎背熊腰的男人,文心一言仍然给出的是字面直译后的图片,画风一言难尽。
即便输入提示词时强调“画一个卫浴器材水龙头”,文心一言画出的仍然是水中龙的头像;当深燃输入“画一个风姿绰约的人”时,系统画出的是一位男士,显然AI没能理解风姿绰约形容的是女人。
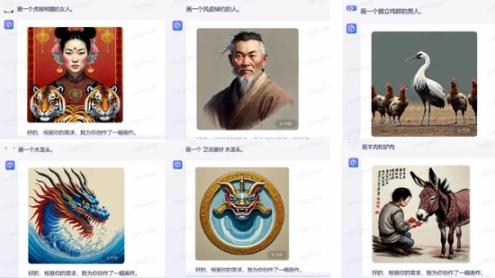
程序员改bug的速度比不上网友找漏洞的速度。很快又有人发现,文心一言画图时有把提示词中译英之后根据英文意思生成图片的可能性,据此有人推测百度可能用国外的作图产品接口,套了一个自己的壳。
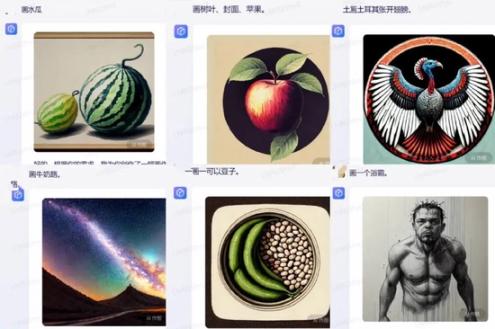
深燃也验证了一下某用户的测试。比如输入“水瓜”,画出的是西瓜,这也对应西瓜的英文单词Watermelon;要求画树叶、封面、苹果,画出的图是树叶覆盖苹果,显然系统是把封面翻译成了Cover,这个单词也有覆盖的意思;画“土耳其张开翅膀”,出现的画面是张开翅膀的火鸡,我们都知道,Turkey是土耳其,也是火鸡。
对此,百度对外回应称,文心一言完全是百度自研的大语言模型,文生图能力来自文心跨模态大模型ERNIE-ViLG。“在大模型训练中,我们使用的是全球互联网公开数据,符合行业惯例。”
亚洲视觉科技研发总监陈经也在接受媒体采访时表示,“百度的画图AI采用了英文标注的开源图片素材进行训练,因此需要中翻英来当prompt(提示词)。目前,全球AI研发有开源的传统,特别是训练数据库,不然收集图片效率太低了。”
深燃体验后还发现,文心一言在单个需求描述时表现尚可,比如画一幅愤怒的小孩、开心的农民、一只很饿的流量猫,但一幅图一旦提出多个作图需求,AI就有点懵。
比如请文心一言“生成一幅画,在一个下雨天,小红在植树,小王在看书”,系统生成的图片里只有背靠树看书的一个人;还有,“画一幅画,里面有大笑的年轻人、哭泣的小孩、愁容满面的老人”,系统把哭泣和愁容满面等表情集合在了一张脸上,画出了一个小孩和老人的结合体。如下图所示,还有一些类似的情况,系统同样没能准确完成给出的指令。
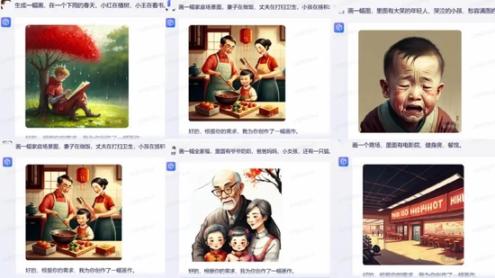
深燃又把上述提示词输入到MidjourneyV4测试了一下,如下图所示,即使是V4版本,表现也远高出文心一言。MidjourneyV4基本能理解句子中的意思,做出的图几乎可以包含所有的要素。

深燃还测试了AI绘画领域一直以来难以攻克的画手指难的问题。在这方面,文心一言也没能经受住考验。比如“画一位30岁的女士,双手竖起大拇指”,文心一言生成的图片大拇指是竖起来了,但是其中一只手有7根手指;输入“画一个人,两只手做点赞姿势”时,系统也无法实现这一手部姿势。
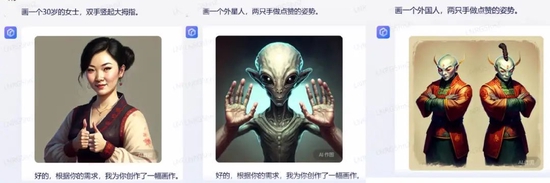
Midjourney此前的版本同样存在手指误差的问题,最新发布的V5版本,已经能够正确画出五根手指,虽然有人依旧指出其绘出的大拇指有点长,但相比以往已经有不小的进步。有从业者评价:“Midjourney的此前版本就像是近视患者没有戴上眼镜,而MidjourneyV5就是戴上眼镜后的清晰效果,4K细节拉满”。
比如MidjourneyV5画出的《三体》角色图,效果被网友评价为几乎要“成精了”。而文心一言画《三体》角色时,系统全然不顾描述里提到的留着黑色短发、戴着眼镜的要求,画出了一个扎着发髻,不戴眼镜,古风穿着的男士。
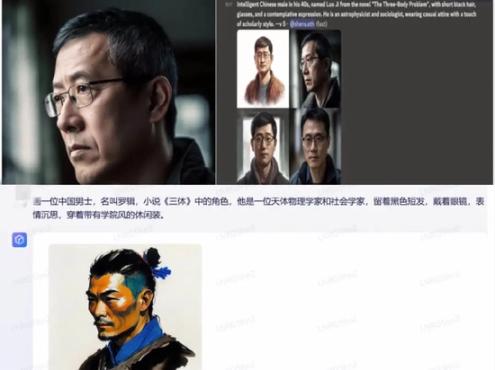
上图为MidjourneyV5生成的三体角色图 图片来源 / Ai总编推书
下图为文心一言作图 / 深燃截图
最近MidjourneyV5画的一对情侣的图片掀起了业内一阵惊呼。作图的提示词是:“一对年轻的情侣穿着牛仔裤和夹克坐在楼顶上”,背景分别是2000年和2023年的北京。最后出图的效果大大超出很多人的想象。深燃把类似表述输入文心一言时,系统直接给出了毫不相关的图片。

右为深燃对比体验文心一言截图
对比来看,Midjourney作图已经在细节上几近完美了,文心一言还处在难以准确分辨字面意思和实际意思的初级阶段。Midjourney提示词描述越详细,生成的图片越精准,文心一言能理解的文字长度有限,过多描述会让它直接报错或者胡乱生成图片。
AI文生图到底有多难?
按出现时间来算,AI绘画算是AI领域的新事物。
公开报道显示,2021年1月,OpenAI发布了两个连接文本与图像的神经网络:DALL?E和 CLIP。DALL?E可以基于文本直接生成图像,CLIP能够完成图像与文本类别的匹配。DALL?E是基于GPT-3的120亿参数版本实现的。
随后在2022年,DALL・E 2、Stable Diffusion等文生图底层大模型发布,带动了应用层的发展,出现了一大批爆款产品,包括Midjourney。2022年也被认为是“AI绘画元年”。
StabilityAI的Stable Diffusion是一个开源模型,很多开发者基于这个模型开发训练出了更多不同的生成模型。国内很多科技公司的AI绘画项目也是由Stable Diffusion提供技术支撑。Midjourney是付费订阅的,公开信息显示,Midjourney每年的收入可能达到1亿美元左右。另外,有AI绘图业务的还有Google、Meta等公司。百度的文心一言和此前就发布的文心一格算是国内最早的具备AI绘画功能的大模型。
文心一言的发布和升级了的MidjourneyV5更是将AI绘画行业推向高潮。这一次迭代是Midjourney自去年推出以来最大的更新,Midjourney也成了目前市面上最先进的AI图像生成器之一。
热度还在继续。最近,行业内又有一系列企业跟进推出AI绘画功能。3月21日,微软宣布,必应搜索引擎接入了OpenAI的DALL・E模型,将AI图像生成功能引入新版必应和Edge浏览器,免费开放。就在同一天,Adobe发布AI模型Firefly,支持用文字生成图像、艺术字体。
可以说,2023年,AI绘画行业迎来了真正的大爆发。
调侃文心一言之余,客观来说,AI生成图片本身就不是一件容易实现的事情。系统的语义理解能力、充分的数据标注、细节处理、用户的提示词选择,都在AI作图中起着重要作用。
AI领域资深从业者郭威告诉深燃,之前AI生成图片只需要确认风格、物品等,用GAN(生成式对抗网络)生成图片。文心一言和Midjourney这一代模型的做法是先理解自然语义,再生成图片。把自然语言输入到系统里,AI对语义的理解和人类的理解不可避免会有偏差。
“更大的难点,还是标注数据。语义比词组的空间更大,需要大量数据,而且标注难度和成本更高。”郭威说。
很多人以为,系统生成图片有误时,后台改一个标注就能矫正系统了。比如生成“驴肉火烧”出了错,只是告诉系统这是一道菜,而不是一头驴就行了,但这种方式只是一对一修改而没有一层层训练,修正了单个错误,并不会增强系统的理解能力,治标不治本。
也就是说,即便是有大量开源的全球数据库图片可以用,国内的系统在中文提示词与英文素材对应方面还需要做大量工作。
另外,AI生成的图片极难完善眼睛、手、脚等部位细节。一直以来,行业内就有“AI不会画手”的说法,很多人判断是不是AI作图,就看图片中的手画得怎么样。“因为深度学习神经网络没有足够的数据学习手指与手指之间的架构逻辑,加上手指关节间特征属于细小颗粒度,生成的手容易出错。”资深AloT算法从业者连路诗说。目前除了MidjourneyV5,其他AI作图产品细节方面的问题还没有完全解决。
到了最终生成图片环节,用户选择用什么提示词(prompt)和风格(style)来生成想要的图片也很重要,新用户往往不得方法,很难找到精准的提示词或足够契合的风格。
此外,目前的AI绘图产品还存在一些共同的挑战。
连路诗提到,一方面是时效性不够,目前AI绘画知识库的更新、数据的引入不完全是实时的,如果加入实时性数据,需要巨大的成本;另一方面,目前各系统对数据过滤的严谨程度不一样,有的设置了相对严格的禁用词,有的没有,法律或道德边界不清。
还有一个是AI绘图带来的版权问题。目前行业内大部分企业不对外宣布自己用来训练AI的图片来源,这样的AI生成图片商用时,可能存在未知的法律风险。且目前AI作的图也不受版权保护。
行业共性问题之外,根据多位从业者的说法,在数据、算法、算力三方面,文心一言都跟Midjourney差距不小。
数据方面,文心一言数据的数量和质量都需要提升。
连路诗解释,NLP(即natural language process,自然语言处理)分成几个过程,第一步是自然语言理解,比如,实体识别,系统会根据专属名词生成自己的理解;接下来是自然语言生成,包括生成文字和图片。大多数问题出在对自然语言的理解不准确,这时候就需要人工对句子进行数据处理、参数调整等。
“中文本身难在字与字之间没有间距,人工分词一方面要隔开字词的间距,同时要界定动词、名词等词性,还要标注主语、谓语、宾语,以及是否为常用词等”,连路诗补充,“分词需要庞大的人力投入,一般一个小组至少需要5000人。AI公司通常把这一需求外包给人力成本较低的省份的公司,另外,AI生成图片的结果也需要人类的反馈增强学习。”
基础标注工作做好之后,系统会将这些词转成向量进行计算,向量越不准确,生成的结果越模糊。“目前百度可能做了一部分工作,但还没达到能准确理解大部分语义的程度,可以判定为不及格。”连路诗说。
陈经也提到,大模型需要的数据库里的“图片是要标注的,这更加大了收集整理图片的难度。当前也有中文标准的训练数据,但是少很多。由于发布时间仓促,百度对于画图AI的中文输入词还没完全搞定,后续应该会根据用户反馈,把中文的提示词与英文的训练素材更好的对应上。”
算法方面,各公司在底层大模型的使用层数上有差别。连路诗认为,以文心一言目前在算法方面的表现来看,有可能与Midjourney等模型的深度神经网络的层数有十倍左右的差距。
“AI生成图片不准确还有一种可能性,该系统的底层架构不是深度神经网络,也没有根据底层Vector(向量)一点点像素级生成图片,而是系统先用搜索引擎匹配知识图谱,再生成图像,也可以理解为拼凑贴图。神经网络在对图片进行计算的时候,本来就有图片的旋转、切割、拼凑,这样的系统生成的图片有可能是颗粒度很粗的片状图片拼凑出来的。”连路诗做了这样的推测。不过,文心一言属于哪种技术还不清楚。
第三,算力上的差距。OpenAI号称自己的模型是千亿规模参数,也就是每次计算的时候拥有1000张以上显卡分布式计算的算力。百度与国外几家主要科技企业的算力差距同样不小。
当然,百度和Midjourney目前的发展程度不一,与其发展阶段也有关系。
Midjourney于2022年3月首次面世,目前已经迭代到了第五代。百度文心一言所具备的AI作图功能,即文心一格,虽然在2022年8月就推出了,但目前没有看到相关的升级迭代信息。而在AI领域,变化几乎是以天为单位的。
国内AI绘图多久能赶上国际水平?郭威对此比较乐观。在他看来,“数据方面虽然有差异,但最多也只有半年左右的差距,中文类的数据国内比国外更多,拼命补一下能赶上。”
至于算法差异,他表示,OpenAI等几家机构比Google、Facebook、百度等高出半年到一年的水平,之前因为不确定性大,各企业没有重点布局,现在验证这条路是有前途的,针对性追赶,很快也能赶上。虽然OpenAI没开源,但从OpenAI出来的一些人很快也会把技术思路共享到小圈子里,头部公司很容易跟进。
“算力的差距就很难弥补了,短期内难追上去,但是用一年多时间把国内系统做到国外80分或90分以上的程度是可能的。”郭威说。
无论如何,接下来,AI绘画将会走到舞台中央大放异彩是确定的事实,对各公司来说,拼的是速度。行业规则是公开的,所有选手都在往前跑,这时候,竞争是最大的动力,拿结果说话才是硬道理。
应受访者要求,文中郭威为化名。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板